본 리뷰에서 이상한 점이 부족한 점이 있다면 피드백 부탁드립니다.
Introduction
- 최근에는 딥러닝이 모델이 Large Datasets을 활용하여 다양한 분야에서 좋은 성과를 가졌다. 그러나 현실에 많은 경우에는 데이터셋의 크기가 부족해 overfitting과 같은 문제가 있다.
- overfitting을 해결하기 위해서 dropout, batch normalization과 같은 기술들이 연구되었지만, low data regimes(적은 데이터 체계? 데이터 도메인? 데이터 사이즈?)에서는 이것조차 의미가 없다.
- random translation, rotations, flips, Gaussian noise 추가 등과 같은 transformation 기법을 통해서 데이터셋을 늘릴 수 있지만, 이는 기존의 ImageNet과 같은 큰 데이터셋에도 좋은 효과를 보는 기법이다.
- 그래서 본 논문에서는 DAGAN을 활용하여 Data augmentation을 진행한다.
- Contribution은 다음과 같다.
- 새로운 GAN을 사용하여 Data Augmentation을 위한 표현과 프로세스를 학습한다.
- 새로운 단일 data point에서 실제 data-augmentation sample을 생성한다.
- low-data regime에서 data augmentation을 위해서 DAGAN을 적용함으로써 모든 과제의 generalization 성능을 크게 향상했음을 입증한다.
- DAGAN은 이전의 meta-learning 모델보다 더 좋은 성능을 보여준다.
Models For Data Augmentation
Data Augmentation Generative Adversarial Network
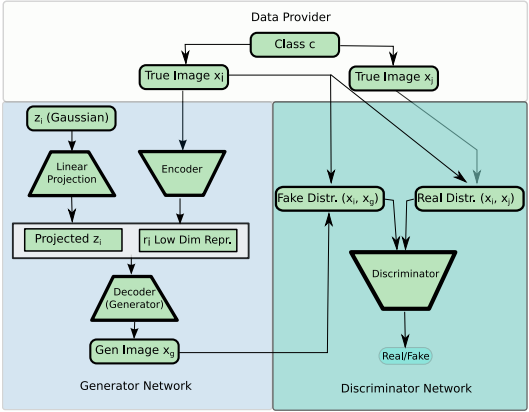
위 그림은 DAGAN 모델의 전반적인 모습을 보여주는 그림이다. 여기서 Generator부분을 수식적으로 간단하게 나타내면 아래와 같다.
$$r=g(x_{input})\\z=N(0,I)\\x_{output}=f(z,r)$$
여기서 $r$은 Generator의 incoder에서 입력으로 받은 $x_{input}$에 대한 representation이고, $z$는 Gaussian 분포로부터 밭은 값은 Linear Projection한 random 값이다.
새로 만들어지는 $x_{output}$는 $r$과 $z$를 입력으로 받아서 Generator의 decoder부분에서 생성한 값이다.
여기서 Generator는 UNet과 Resnet을 합친 UResNet을 사용하였고, Discriminator는 DenseNet을 사용하여 구현하였다. 각 모델의 자세한 내용은 논문에 상세히 적혀있다. (추후 추가하겠습니다.)
Learning
본 논문에서는 improved WGAN을 사용하며, 다음 두 가지를 받는다.
- 입력값 $x_i$와 $x_i$와 같은 클래스인 $x_j$
- 입력값 $x_i$와 $x_i$로부터 생성된 $x_g$
discriminator는 1과 2를 구별하도록 학습이 진행된다. 즉, 1의 distribution과 2의 distribution을 구별할 수 있도록 WGAN crit을 사용하여서 학습한다.
본 논문에서는 DAGAN을 학습시킬 때 500 epochs, 0.0001 learning rate로 adam($\beta_1=0,\ \beta_2=0.9$)를 사용했다.
Dataset
본 논문에서는 Omniglot, EMNIST, VGG 데이터셋이 사용되었다.
DAGAN Training and genenration

여러 가지 architecture에서 omniglot 데이터셋을 학습시킨 모습이다.


위 이미지는 왼쪽 상단의 Face이미지를 기준으로 DAGAN이 생성한 이미지이다.

위 table은 각 데이터셋 별로 DAGAN을 사용여부에 따른 Classifier의 성능을 나타낸 표이다. 표에서도 보이듯이 전반적으로 DAGAN을 사용하여 학습하였을 경우 성능이 좋아졌다.